1、首先下载安装weka
http://www.cs.waikato.ac.nz/ml/weka/downloading.html
2、打开weka,选择第一项Explorer
3、准备数据集文件,在weka中,一般数据文件为:xxx.arff,比如我编辑一个文件叫做tumor.arff,文件的内容为:
@RELATION tumor
@ATTRIBUTE size NUMERIC
@ATTRIBUTE 'Class' {'1','0'}@DATA
0.0,'0'0.1,'0'0.7,'1'1.0,'0'1.1,'0'1.3,'0'1.4,'1'1.7,'1'2.1,'1'2.2,'1'稍微解释一下数据,size属性表示tumor的大小,被单引号括起来的Class应该是weka中的保留字,专门表示类别。
4、加载数据。在主界面的Preprocess选项卡下,点Open file,然后选择第三步中准备好的数据文件:tumor.arff
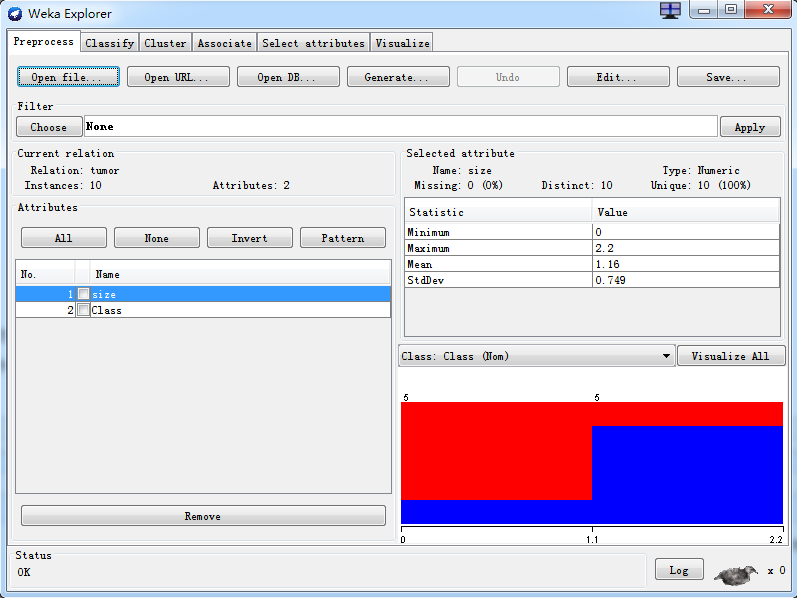
在这个界面下,可以看到关于数据的一些统计信息,以及一些图形化的显示,同学们可以自己探索。
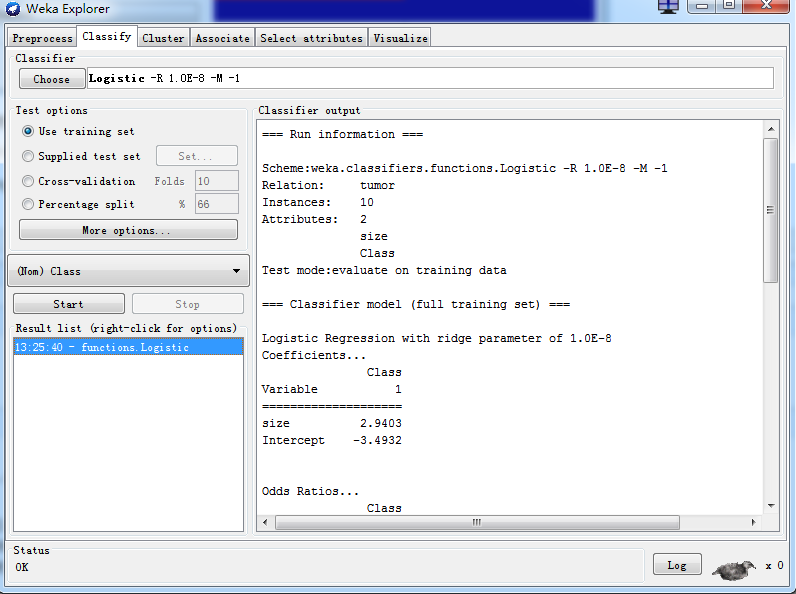
6、切换到主界面的Classify选项卡,点击Choose,在functions分支下面选择Logistic。
Test options选择Use training set,然后点击Start即可
7、再给出一组测试数据:
@RELATION tumor
@ATTRIBUTE x1 NUMERIC@ATTRIBUTE x2 NUMERIC@ATTRIBUTE 'Class' {'1','0'}@DATA
0.0 2.9 '0' 1 1.9 '0' 2.0 0.9 '0' 3.0 -0.1 '0' 4.0 -1.1 '0' 0.0 2.5 '0' 1 1.5 '0' 2.0 0.5 '0' 3.0 -0.5 '0' 4.0 -1.5 '0' 0.0 2.0 '0' 1 1 '0' 2.0 0.0 '0' 3.0 -1 '0' 4.0 -2.0 '0' 0.0 1 '0' 1 0.0 '0' 2.0 -1 '0' 3.0 -2.0 '0' 4.0 -3.0 '0'0.2 2.9 '1' 1.2 1.9 '1' 2.2 0.9 '1' 3.2 -0.1 '1' 4.2 -1.1 '1' 1.2 2.9 '1' 2.2 1.9 '1' 3.2 0.9 '1' 4.2 -0.1 '1' 5.2 -1.1 '1' 2.2 2.9 '1' 3.2 1.9 '1' 4.2 0.9 '1' 5.2 -0.1 '1' 6.2 -1.1 '1'3.0 0.2 '0'1 2.3 '0'1 1.8 '1'2.0 0.8 '1'weka训练结果:
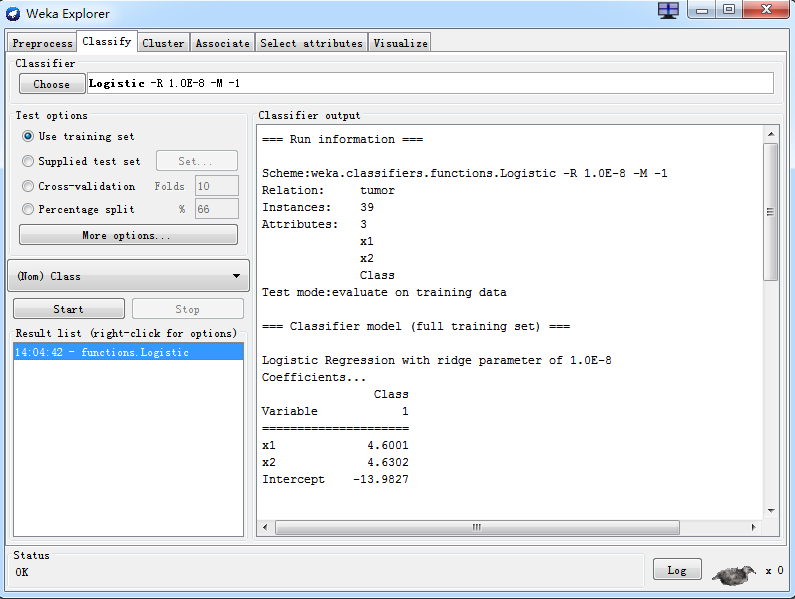
训练出来的模型是:h(x)=1/(1+exp(-(-13.9827+4.6001*x1+4.6302*x2)))